ㅇ 다형성(polymorphism)
한 마디로 정리하면, 하나의 객체가 여러가지 형태를 가질 수 있는 성질이다.
자바에선, 한 타입의 참조 변수를 통해 여러 타입의 객체를 참조할 수 있도록 만든 것을 의미한다.
Friend라는 상위 클래스가 있고, BoyFriend, GirlFriend 라는 클래스가 Friend클래스를 상속받는다.
그럴 때, 객체 생성을
Friend friend = new Friend();
BoyFriend boyfirend = new BoyFriend();
Friend girlfriend = new GirlFriend(); // 이렇게 하거나,
GirlFriend girlfriend2 = new GirlFriend(); // 이렇게 할 수 있다.
//GirlFriend friend2 = new GirlFriend(); // 하위클래스 타입으로는 객체생성 불가능!타입변환도 가능하다.
public class VehicleTest {
public static void main(String[] args) {
Car car = new Car();
Vehicle vehicle = (Vehicle) car; // 상위 클래스 Vehicle 타입으로 변환(생략 가능)
Car car2 = (Car) vehicle; // 하위 클래스 Car타입으로 변환(생략 불가능)
MotorBike motorBike = (MotorBike) car; // 상속 관계가 아니므로 타입 변환 불가 -> 에러발생
}
}이렇게 다형성을 잘 활용하면 많은 중복되는 코드를 줄일 수 있다.
ㅇ 추상화
자바에서 추상화 라는 개념을 알기 위해선, abstract 제어자를 알아야 한다.
메서드 앞, 클래스 앞에 사용하며 사용하게 되면 각각 추상 메서드, 추상 클래스가 된다. 이것들은 '미완성' 이다. 고로,
상속받아서, '완성' 시켜야 하는것이다.
abstract class Animal{
public String kind;
public abstract void sound();
}
class Dog extends Animal{
public Dog(){
this.kind = "포유류";
}
public void sound(){
System.out.println("왈왈");
}
}
class Fish extends Animal{
public Fish(){
this.kind = "어류";
}
public void sound(){
System.out.println("뻐끔뻐끔");
}
}이렇게 객체의 공통적인 속성,기능을 추출해 정의하는 것이다.
ㅇ final
final 키워드는 필드, 지역 변수, 클래스 앞에 위치 할 수 있다.
이 키워드가 붙은 클래스는 변경,확장이 불가하고, 메서드는 오버라이딩이 불가능하고, 변수는 상수가 된다.

내가 만든 프로젝트에서도 사용했듯이, 바뀌지 말아야할 곳에 final을 사용한다. 이렇게하면 절대 바뀌지 말아야 할 값들을 고정 시킬 수 있다.
ㅇ interface
인터페이스는 클래스의 구조와 비슷하다. 대신 class 대신 interface를 사용한다. 그리고 내부의 모든 필드가 public static final로 정의 된다. 메서드는 모두 public abstract로 정의되야한다.
public interface Ex{
public static final int a = 1;
final int b = 2; //public static 생략
static int c = 3; //public & final 생략
public abstract String abc();
void cba() // public abstract 생략
}이렇게 만든 인터페이스를 구현할 땐,
class 클래스명 implements 인터페이스명{
}
이런 구조로 구현하고, 꼭! 인터페이스에 있는 모든 추상 메서드를 구현해야 한다.
자바에선, 다중 상속은 허용되지 않는데, 인터페이스는 가능하다.
class ExClass implements ExInterface1, ExInterface2 . . . {
. . .
}
왜 굳이 이렇게 사용할까?
-- > 선언과 구현을 분리 시켜 개발시간을 단축할 수 있고, 독립적인 프로그래밍을 통해 한 클래스의 변경이 다른 클래스에 미치는 영향을 최소화 시킬 수 있다는 장점이 있다!
ㅇ 열거형(Enum)
서로 연관된 상수들의 집합을 의미함. final 키워드를 사용해 선언할 수 있는데, public static final int a = 1;이런식으로 상수를 설정 할 수 있다. 내가 작성한 코드에도 enum을 사용했는데, 한번 보자.
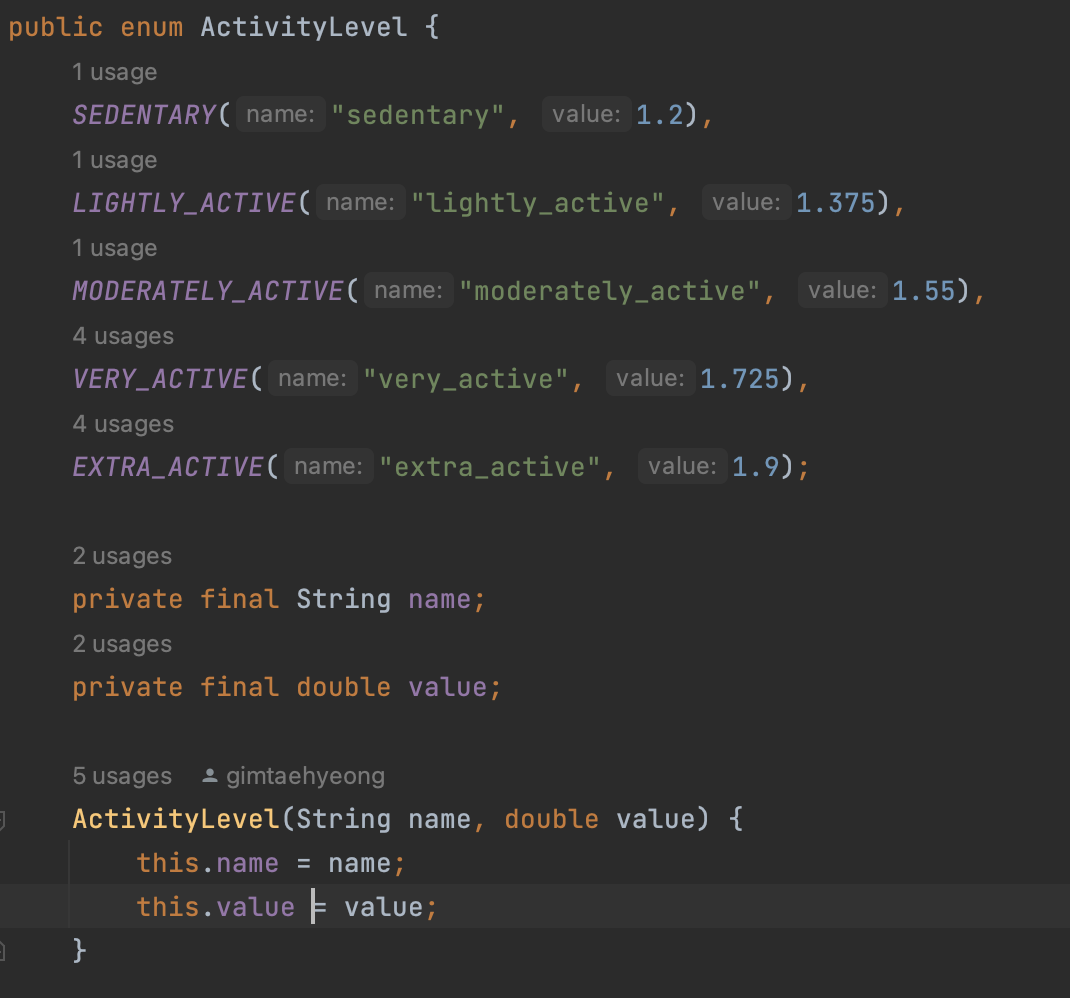
사용자의 유지 칼로리 계산 메서드에 필요한 정보인 사용자의 활동 정도를 enum으로 표현했다.
저렇게 상수들을 모아서 사용할때, 매우 유용한 방법이다. 그리고 상수명은, 대문자로 표현한다. 나는 값을 따로 지정해줬지만, 안해주면 순서대로 0부터 1씩 더해지며 값이 지정된다.
ㅇ 제네릭(Generic)
솔직히 기억안났던 부분이다. 나중에 써봐야징
여러가지의 타입을 가진 인스턴스를 만들기 위해 사용함.
class Basket<T> {
private T item;
public Basket(T item){
this.item = item;
}
public T getItem() {
return item;
}
public void setItem(T item) {
this.item = item;
}
}위의 Basket 클래스를 인스턴스화 해보자.
Basket<String> basket1 = new Basket<String>("아무말");이건 Basket 클래스 내의 T를 String 으로 바꿔라 와 같은 의미다.
제네릭 클래스에선 타입 매개변수를 사용할 수 없다.
class Basket<T>{
private T item1; // O
static T item2; // X만약 타입 매개변수에 치환될 타입으로 int나 double 같은 기본타입을 지정하고 싶다면 래퍼 클래스를 활용하자. int - Integer, double - Double
ㅇ 예외처리
컴파일 에러 - 자바 컴파일러가 잡아내는 오탈자나, 잘못된 자료형, 등등 IDE가 잡아내는 빨간 줄같은 것들.
런타임 에러 - 런타임 시 발생하는 에러를 나타냄. 런타임 에러는 주로 컴퓨터가 수행할 수 없는 특정한 작업을 요청할 때 발생함. JVM이 감지함.
예외 - 잘못된 사용 또는 코딩으로 인한 상대적으로 미약한 수준의 오류, 수습이 가능한 오류를 지칭함.
try - catch문
try {
//예외 발생 가능성 있는 코드 삽입
}
catch (ExceptionType1 e1){
//ExceptionTyple1 예외 발생 시 실행할 코드
}
catch (ExceptionType2 e2){
//ExceptionType2 예외 발생 시 실행할 코드
}
finally{
// finally는 써도 되고 안써도 됨.
// 예외 발생 여부와 상관없음. 항상 실행
}내가 실제로 예외처리를 한부분은 이렇게 했다.



팀원분이 예외처리부분을 따로 만들어주셔서 ExceptionCode만 작성해 사용할 수 있었다.
두번째 BusinessLogicException클래스는 RuntimeException클래스를 상속한다.
ㅇ 컬렉션 프레임워크
컬렉션이란, 여러 데이터의 집합을 의미함. 여러 데이터 그룹으로 묶어놓은 것을 컬렉션이라고 하고, 편리한 메서드들을 미리 정의해 둔 것을 컬렉션 프레임워크라고 한다. 실제로 정말 많이 사용하고 알고리즘문제에서도 자주 사용한다.
Collection은 List, Set으로 나뉘고, Map은 Hashtable, HashMap, SortedMap으로 나뉜다.
솔직히 List나 HashMap, Set 빼고는 기억도안난다ㅋ
먼저 List
List는 데이터의 순서가 유지 된다. 중복 저장이 가능한 컬렉션을 구현하는 데 사용한다.
Set은 데이터의 순서가 유지되지 않으며, 중복저장이 불가능한 컬렉션을 구현하는 데 사용한다.
Map은 키와 값의 쌍으로 데이터를 저장하는 컬렉션을 구현하는데 사용된다.
ㅇ 컬렉션의 메서드
| 기능 | 리턴타입 | 메서드 | 설명 |
| 객체 추가 | boolean | add(Object o) / addAll(Collection c) |
주어진 객체 및 컬렉션의 객체들을 컬렉션에 추가합니다. |
| 객체 검색 | boolean | contains(Object o) / containsAll(Collection c) | 주어진 객체 및 컬렉션이 저장되어 있는지를 리턴합니다. |
| Iterator | iterator() | 컬렉션의 iterator를 리턴합니다. | |
| boolean | equals(Object o) | 컬렉션이 동일한지 확인합니다. | |
| boolean | isEmpty() | 컬렉션이 비어있는지를 확인합니다. | |
| int | size() | 저장된 전체 객체 수를 리턴합니다. | |
| 객체 삭제 | void | clear() | 컬렉션에 저장된 모든 객체를 삭제합니다. |
| boolean | remove(Object o) / removeAll(Collection c) | 주어진 객체 및 컬렉션을 삭제하고 성공 여부를 리턴합니다. | |
| boolean | retainAll(Collection c) | 주어진 컬렉션을 제외한 모든 객체를 컬렉션에서 삭제하고, 컬렉션에 변화가 있는지를 리턴합니다. | |
| 객체 변환 | Object[] | toArray() | 컬렉션에 저장된 객체를 객체배열(Object [])로 반환합니다. |
| Object[] | toArray(Object[] a) | 주어진 배열에 컬렉션의 객체를 저장해서 반환합니다. |
ㅇ List 인터페이스에서 사용되는 메서드
| 기능 | 리턴 타입 | 메서드 | 설명 |
| 객체 추가 | void | add(int index, Object element) | 주어진 인덱스에 객체를 추가 |
| boolean | addAll(int index, Collection c) | 주어진 인덱스에 컬렉션을 추가 | |
| Object | set(int index, Object element) | 주어진 위치에 객체를 저장 | |
| 객체 검색 | Object | get(int index) | 주어진 인덱스에 저장된 객체를 반환 |
| int | indexOf(Object o) / lastIndexOf(Object o) | 순방향 / 역방향으로 탐색하여 주어진 객체의 위치를 반환 | |
| ListIterator | listIterator() / listIterator(int index) | List의 객체를 탐색할 수 있는 ListIterator 반환 / 주어진 index부터 탐색할 수 있는 ListIterator 반환 | |
| List | subList(int fromIndex, int toIndex) | fromIndex부터 toIndex에 있는 객체를 반환 | |
| 객체 삭제 | Object | remove(int index) | 주어진 인덱스에 저장된 객체를 삭제하고 삭제된 객체를 반환 |
| boolean | remove(Object o) | 주어진 객체를 삭제 | |
| 객체 정렬 | void | sort(Comparator c) | 주어진 비교자(comparator)로 List를 정렬 |
ArrayList<타입매개변수> 객체명 = new ArrayList<타입 매개변수>(초기 저장 용량 기본 10);
LinkedList<타입매개변수> 객체명 = new LinkedList<>();ㅇ set의 메서드
| 기능 | 리턴 타입 | 메서드 | 설명 |
| 객체 추가 | boolean | add(Object o) | 주어진 객체를 추가하고, 성공하면 true를, 중복 객체면 false를 반환합니다. |
| 객체 검색 | boolean | contains(Object o) | 주어진 객체가 Set에 존재하는지 확인합니다. |
| boolean | isEmpty() | Set이 비어있는지 확인합니다. | |
| Iterator | Iterator() | 저장된 객체를 하나씩 읽어오는 반복자를 리턴합니다. | |
| int | size() | 저장된 전체 객체의 수를 리턴합니다. | |
| 객체 삭제 | void | clear() | Set에 저장된 모든 객체를 삭제합니다. |
| boolean | remove(Object o) | 주어진 객체를 삭제합니다. |
HashSet<리턴타입> 객체명 = new HashSet<리턴타입>();
TreeSet<리턴타입> 객체명 = new TreeSet<>();HashSet은 중복된 값을 허용하지 않으며, 저장 순서를 유지하지 않음.
TreeSet은 이진 탐색 트리 형태로 데이터를 저장하고, 중복저장을 허용하지 않고, 저장 순서를 유지 하지 않음. 정렬과 검색에 특화된 자료구조다.
ㅇ Map 의 메서드
| 기능 | 리턴 타입 | 메서드 | 설명 |
| 객체 추가 | Object | put(Object key, Object value) | 주어진 키로 값을 저장합니다. 해당 키가 새로운 키일 경우 null을 리턴하지만, 같은 키가 있으면 기존의 값을 대체하고 대체되기 이전의 값을 리턴합니다. |
| 객체 검색 | boolean | containsKey(Object key) | 주어진 키가 있으면 true, 없으면 false를 리턴합니다. |
| boolean | containsValue(Object value) | 주어진 값이 있으면 true, 없으면 false를 리턴합니다. | |
| Set | entrySet() | 키와 값의 쌍으로 구성된 모든 Map.Entry 객체를 Set에 담아서 리턴합니다. | |
| Object | get(Object key) | 주어진 키에 해당하는 값을 리턴합니다. | |
| boolean | isEmpty() | 컬렉션이 비어 있는지 확인합니다. | |
| Set | keySet() | 모든 키를 Set 객체에 담아서 리턴합니다. | |
| int | size() | 저장된 Entry 객체의 총 갯수를 리턴합니다. | |
| Collection | values() | 저장된 모든 값을 Collection에 담아서 리턴합니다. | |
| 객체 삭제 | void | clear() | 모든 Map.Entry(키와 값)을 삭제합니다. |
| Object | remove(Object key) | 주어진 키와 일치하는 Map.Entry를 삭제하고 값을 리턴합니다. |
HashMap<String, Integer> hashmap = new HashMap<>();
Hashtable<String, String> map = new Hashtable<String, String>();HashMap은 키와 값으로 구성된 객체를 저장함. 이를 Entry 객체라고 함.
저장되는 위치는 해시 함수를 통해 결정됨. 많은 양의 데이터를 검색하는데 있어 뛰어난 성능을 보임.
Hashtable은 HashMap과 사용법이 거의 동일하다. key, value는 중복x.
차이는 Tread-safe하다는것과, key에 null허용 x(HashMap에선 가능)하다는것이 있다.
ㅇ 애너테이션(annotation)
쉽게말해, 컴퓨터에게 알려주는 주석같은느낌이다.(개인적인 느낌)
컴파일러 또는 다른 프로그램에 필요한 정보를 제공해주는 역할을 한다.
종류로는 자바에서 제공하는 표준 애너테이션, 애너테이션을 정의하는 메타 애너테이션이 있다.
스프링을 사용하면 엄청많이 사용하게 된다.

내가 만든 컨트롤러의 모습이다. 노란색은 전부 애너테이션이다.
실제로 코딩을 하다보면 엄청나게 많은 애너테이션을 사용하게된다.
표준 애너테이션, 메타 애너테이션 말고도 사용자 정의 애너테이션이 존재한다.
사용하는 방법을 먼저 보자.
@interface 애너테이션명 {
타입 요소명();
}실제로 우리팀원분들이 만든 애너테이션을 보자.

한글 욕을 필터링하는 애너테이션이다. 대충 이런느낌이다.
ㅇ 람다식
여기부턴 3편에 계속..
'Java > 자바공부' 카테고리의 다른 글
| 부트캠프가 끝난뒤...(5) (0) | 2023.05.11 |
|---|---|
| 부트캠프가 끝난뒤...(4) (0) | 2023.05.03 |
| 부트캠프가 끝난뒤...(3) (0) | 2023.04.27 |
| 부트캠프가 끝난뒤...(1) (0) | 2023.04.11 |
| setter 대신 builder (0) | 2023.04.09 |


